
Benchmarking image generation methods against DALL-E 2
In this post, we will benchmark some recently proposed text-to-image generation methods against DALL·E 2 by trying to reproduce Figure 1 in the DALL·E 2 paper (the header image) with each one of them. Is it useful? No. Will it make science advance in any significant direction or bring new insights? Absolutely not. It will, however, be a fun and maybe even interesting exercise.
DALL·E 2 is capable of generating extremely high-quality and detailed images from any text prompt and is possibly the best known among this family of models due to the attention it has received from the media. Although Imagen by Google Brain has already set a new state of the art, DALL·E 2 is still a good reference for this experiment.
These are the models that we will benchmark against DALL·E 2 (don’t worry, we will briefly review each one of them in turn):
- VQGAN
- ruDALL·E
- Disco Diffusion
- DALL·E-mini
We will provide each of these models with the same prompts and see what we get. But first of all, let’s remember what we are trying to achieve.
DALL·E 2 results
For easier reference, the prompts are:
-
vibrant portrait painting of Salvador Dalí with a robotic half face
-
a shiba inu wearing a beret and black turtleneck
-
a close up of a handpalm with leaves growing from it
-
an espresso machine that makes coffee from human souls, artstation
-
panda mad scientist mixing sparkling chemicals, artstation
-
a corgi’s head depicted as an explosion of a nebula
-
a dolphin in an astronaut suit on saturn, artstation
-
a propaganda poster depicting a cat dressed as french emperor napoleon holding a piece of cheese
-
a teddy bear on a skateboard in times square

The figure is taken from the DALL·E 2 paper. We can see the provided prompt and the resulting (hand-picked) image. The quality, level of detail, and fidelity to the prompt are simply amazing.
VQGAN
VQGAN proposes the use of a Transformer to model the image as a sequence of tokens. Instead of working over pixels, these tokens are indices on a discrete codebook. To this end, they train a CNN encoder E and a CNN decoder D such that taken together, they learn to represent images with codes from a learned, discrete codebook. They also use an adversarial approach by adding a discriminator D to ensure good perceptual quality. It’s probably much better explained in this figure:
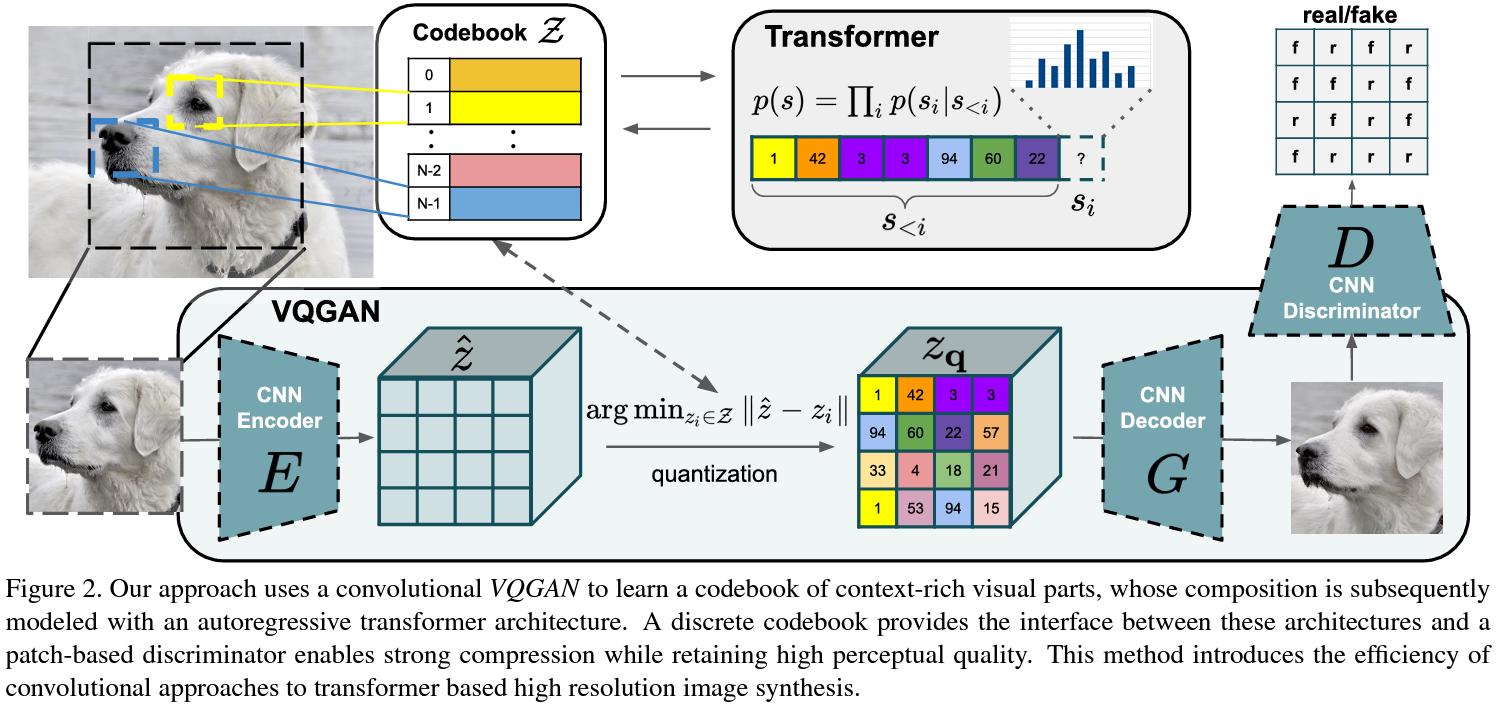
We will use the notebook created by Katherine Crowson (https://github.com/crowsonkb, https://twitter.com/RiversHaveWings) where the technique is extended to use CLIP guidance. These are our VQGAN results:

ruDALL·E
DALL·E is a transformer-based autoregressive model. It jointly models the text description and the image as a single stream of tokens and is trained to generate all of the tokens one after the other. That’s why, given the text description, it can generate the image. The text is represented by, at most, 256 byte pair-encoded tokens, and the image by 1024 tokens created by compressing a 256x256 image to a 32x32 grid of tokens using a discrete variational autoencoder. The original model by OpenAI has not been open to the public, but there are a few Open Source versions. One of them is ru-DALL·E.
ruDALL·E is a DALL·E model created by a Russian company. We have already talked about it before, so on to the results:

Disco Diffusion
Diffusion models learn to produce a slightly more denoised signal x_{t-1} from a noised signal x_t. Sampling starts with noise x_T and produces gradually less-noisy samples x_{T−1}, x_{T−2},… until reaching a final sample x_0. Disco-diffusion is a community-developed notebook that we have already covered in detail a few times.

DALL·E-mini
DALL·E-mini is a more recent, community-developed version of DALL·E. It has gone viral in the last few days. The key, I think, is its ability to generate images that are good quality but just uncanny enough for the memes. We will use the latest available checkpoint at the time of writing since model training is still underway. Let’s see how it does in our task:

Conclusion
That’s it. I told you from the beginning it wasn’t going to be useful or insightful.
I think the exercise is interesting, however, because it highlights the long way we have gone from the beginning to DALL·E-mini and, at the same time, how much improvement is needed to reach the level of DALL·E 2 or Imagen. Indeed, we have left behind some remarkable models, like GLIDE or Make-A-Scene that lie somewhere between DALL·E and DALL·E 2, bridging that gap. Unfortunately, to the best of my knowledge, there are no open source versions available for these models.
It is worth noting, however, that we have been doing a quite biased comparison. The prompts we have tried to reproduce are extremely difficult and were chosen by the DALL·E 2 paper authors because they allow their model to fully shine. For easier prompts, like landscapes or architectures, the simpler models can also achieve extremely good results. We can not judge Disco Diffusion, to name just one model, by these results alone; it is indeed an awesome tool.